The following article shows how to run an event-driven pipeline in Azure Data Factory to process SAP data extracted with Xtract Universal into an Azure Storage.
About #
Xtract Universal is a universal SAP extraction platform that is used in this example to extract and upload SAP customer master data to Azure Storage.
An event then triggers an ADF pipeline to process the SAP parquet file, e.g. with Databricks.
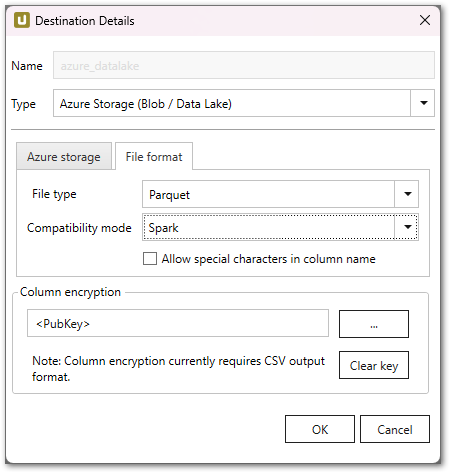
Xtract Universal supports different file formats for Azure storage, this example uses Apache Parquet, which is a column file format that provides optimizations to speed up queries and is more efficient than CSV or JSON.
Target audience: Customers who utilize Azure Data Factory (ADF) as a platform for orchestrating data movement and transformation.
Note: The following sections describe the basic principles for triggering an ADF pipeline. Keep in mind, it is not a best practice document or a recommendation.
Prerequisites #
- You are familiar with Xtract Universal and have created a number of extractions, see Getting Started with Xtract Univeral.
- You are familiar with Azure Storage.
- You can successfully execute extractions from a web browser, see Running an Extraction: URL and command-line.
- You have assigned an Azure Storage Destination to extractions.
- You have access to Azure Data Factory and are familiar with the basic principles of how to build an ADF pipeline.
- You are familiar with ADF pipeline triggers, especially triggering a pipeline in response to a storage event.
General Overview #
Azure Storage
Xtract Universal extracts SAP data and loads it into an Azure Storage as a parquet file. An Azure Storage event trigger is used to run an ADF pipeline for further processing of the SAP file.
ADF Pipelines and Storage Event Triggers
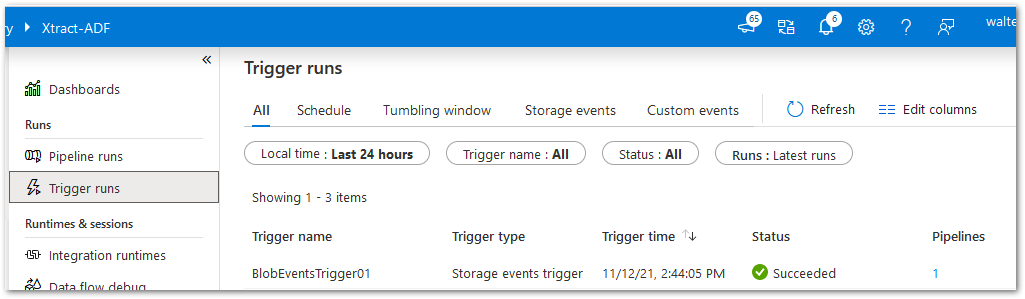
The Master pipeline is triggered by an Azure Storage event and calls a child pipeline for further processing. The Master pipeline has an event trigger based on Azure storage.
The Master pipeline has 2 activities:
- write a log to an Azure SQL database (optional)
- call a Child pipeline to process the parquet file with Databricks
This article focuses on the Master pipeline.
The Child pipeline processes the parquet file e.g., with Databricks. The Child pipeline in this example is a placeholder.
Use Azure SQL for logging (optional)
In the scenario depicted, the ADF pipeline executes a stored procedure to log various details of the pipeline run into an Azure SQL table.
Procedure #
-
Define an SAP extraction and set the destination to Azure Storage.
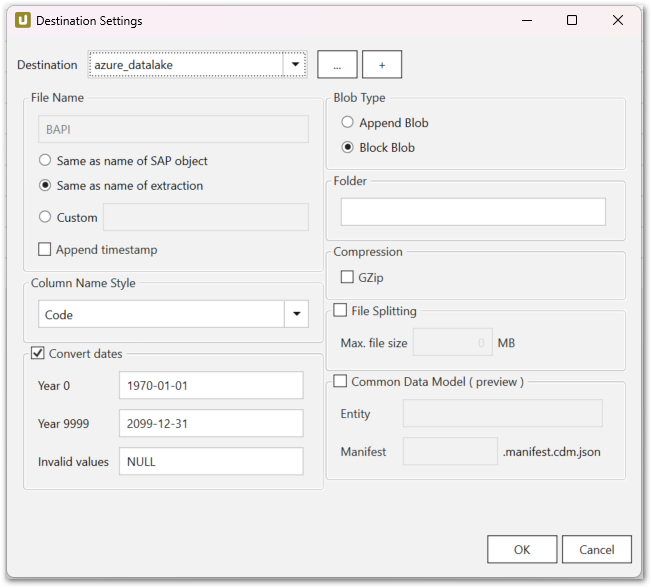
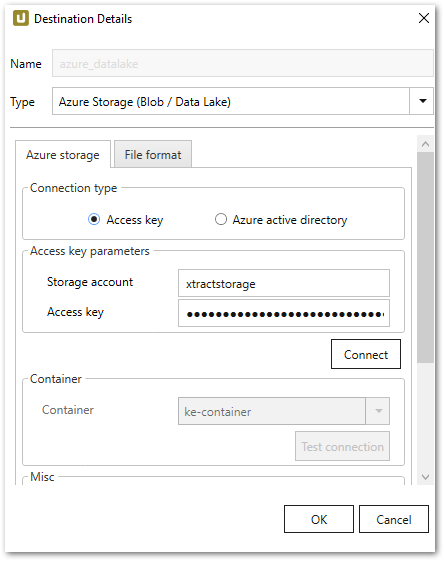
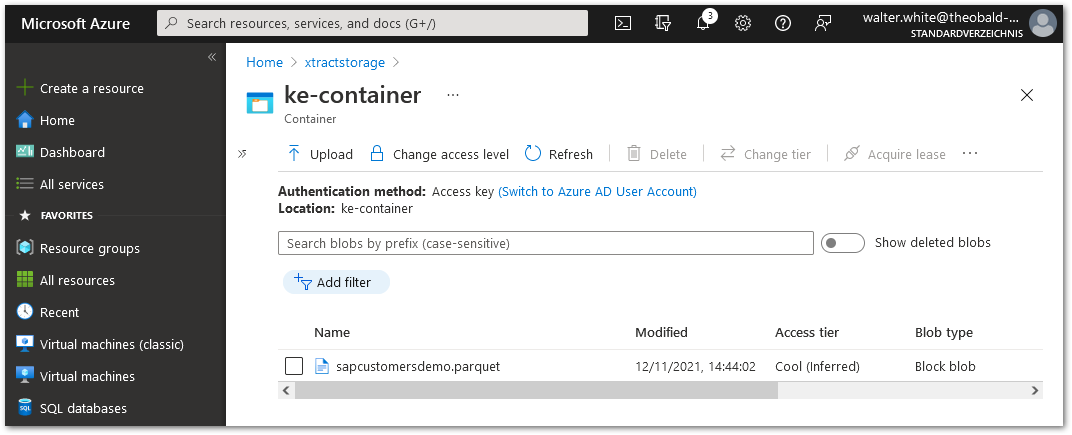
In this example xtractstorage is the storage account and the container is called ke-container:
- Define two pipelines in ADF:
- a master pipeline, here: ProcessBlogStorageFile
- a child pipeline, here: ProcessWithDataBricks
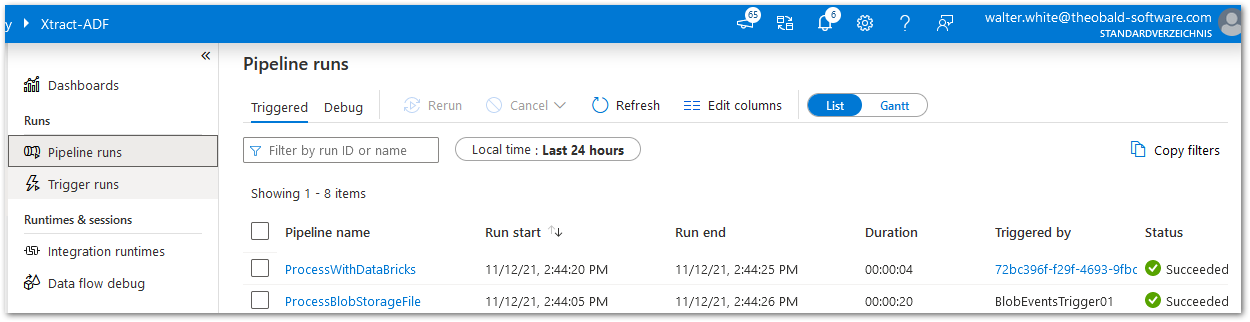
The Master pipeline contains two activities:
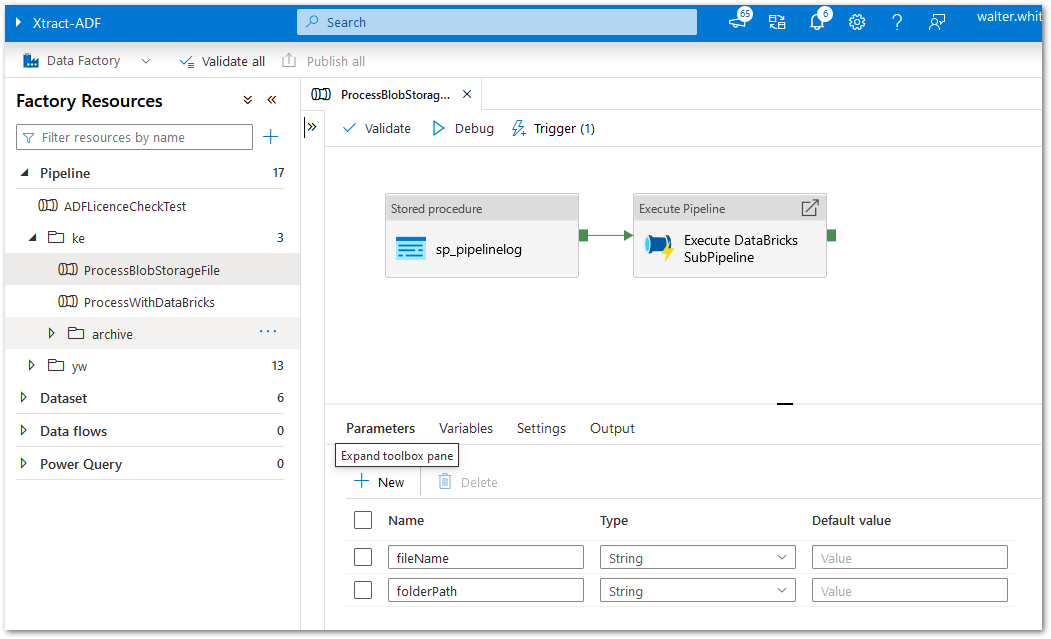
The first activity sp_pipelinelog executes an SQL stored procedure to write a log entry to an Azure SQL table. The second activity runs a dummy subpipeline. As both activities are out of the scope of this article, there are no further details.
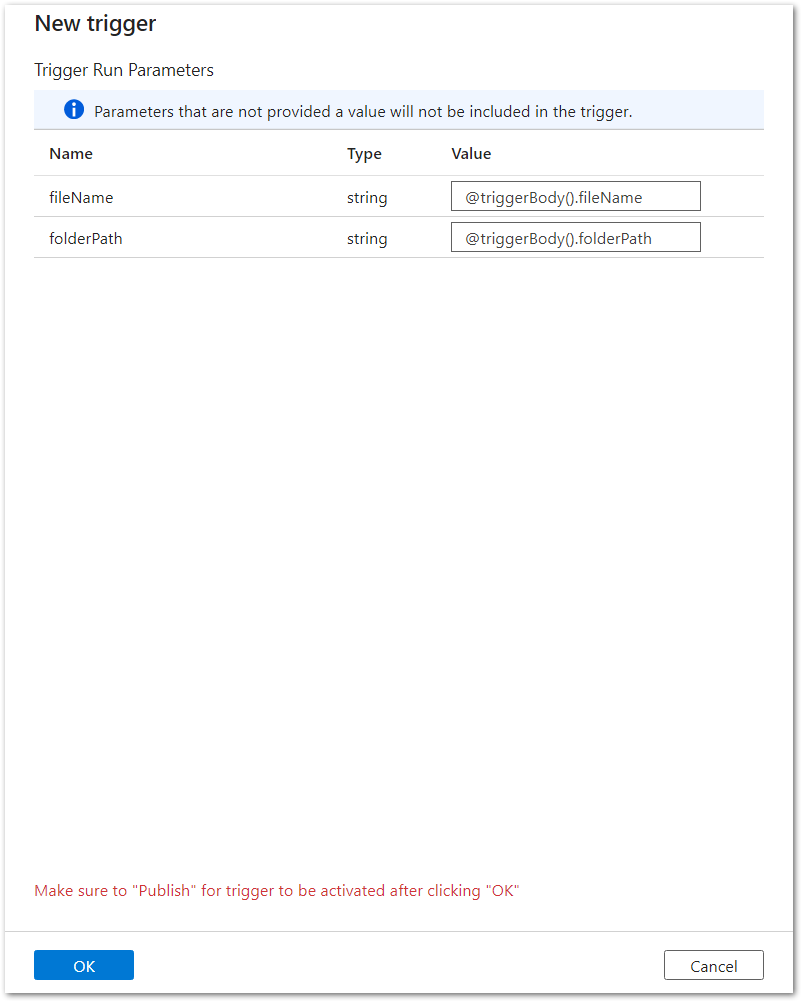
- Define the following parameters:
- fileName: contains the file Name in the Azure Storage.
- folderPath: contains the file path in the Azure Storage.
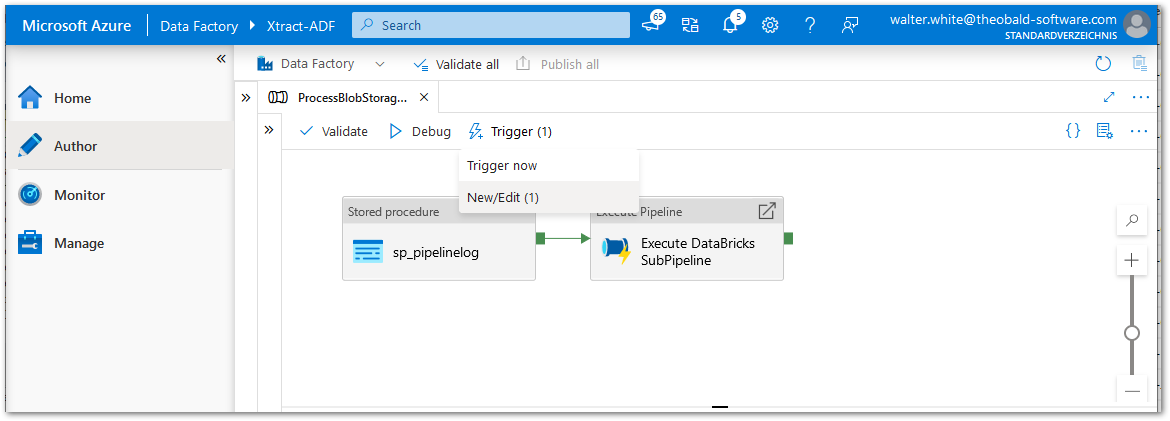
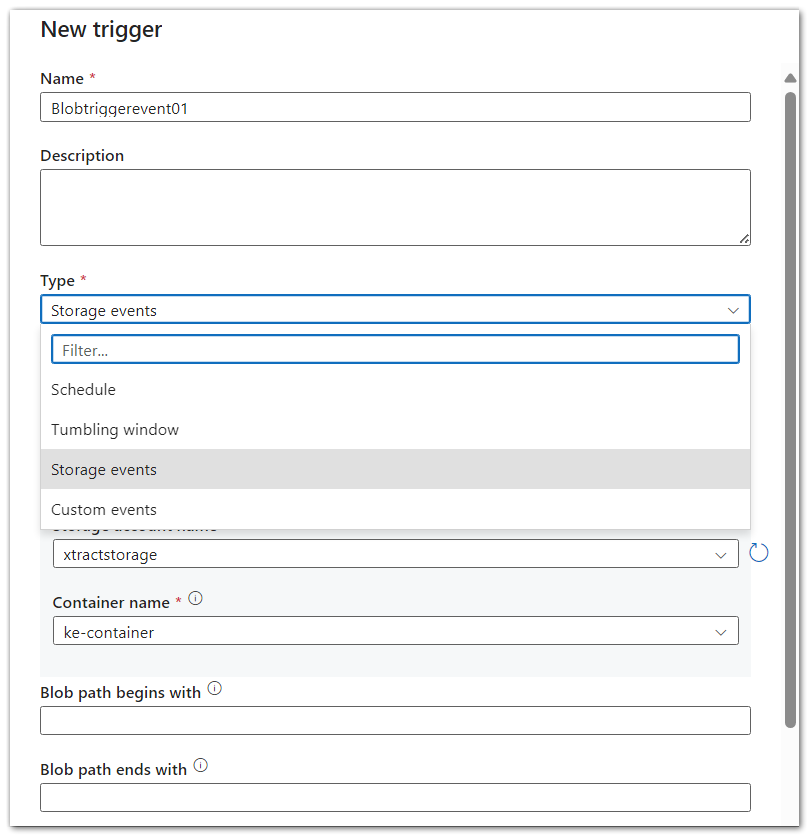
- Click [New/Edit] to add a new Storage Event Trigger in the ADF Pipeline.
-
Adjust the details and use the Storage account name and Container name defined in the Xtract Universal Azure Storage destination:
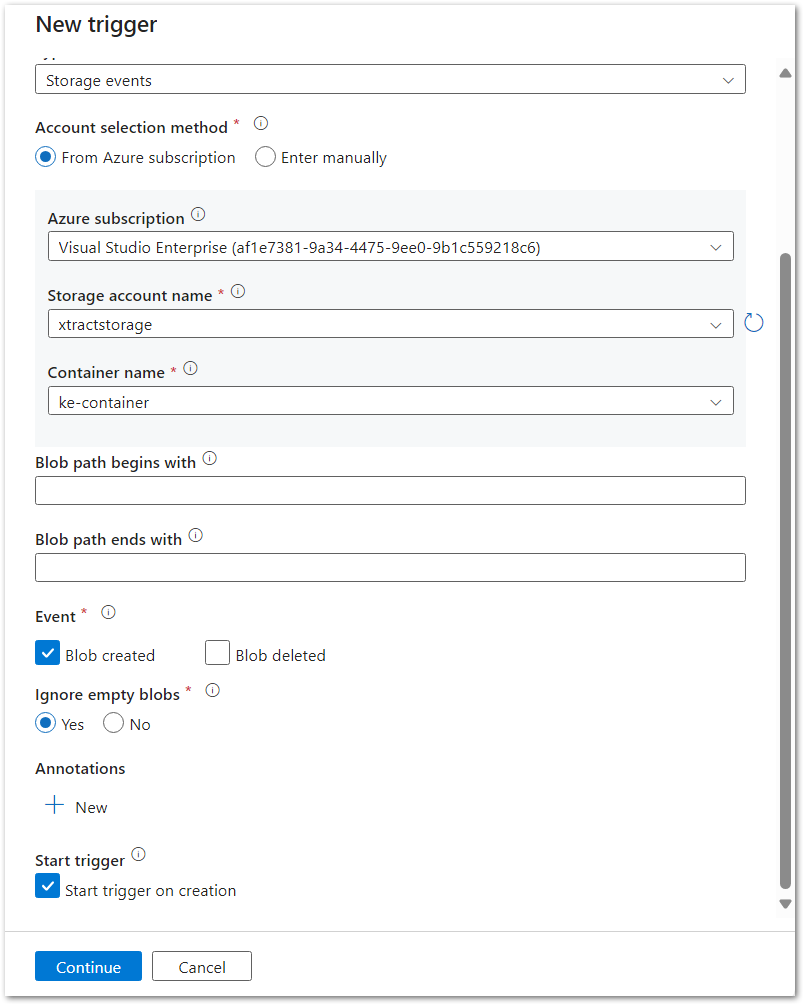
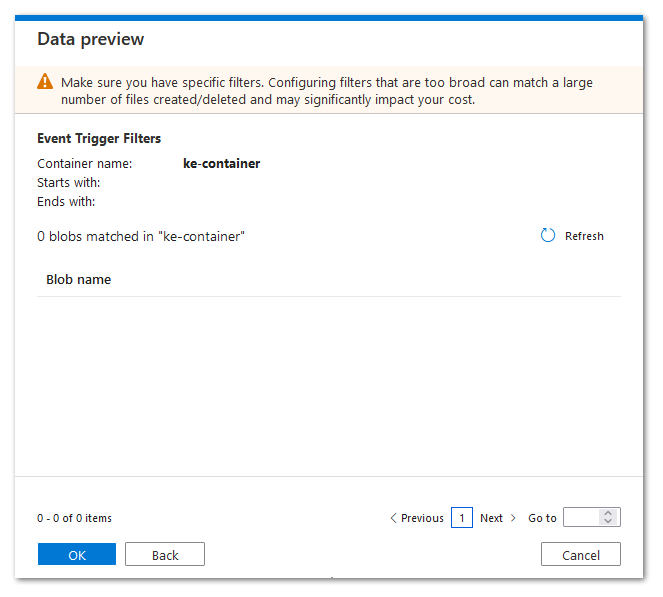
- Adjust the event trigger parameters that are used as input parameters for the Master Pipeline:
- @triggerBody().fileName
- @triggerBody().folderPath
- @triggerBody().fileName
- Publish the pipeline.
- Run the SAP Extraction in Xtract Universal.
- When the extraction is finished, check the Azure Storage.
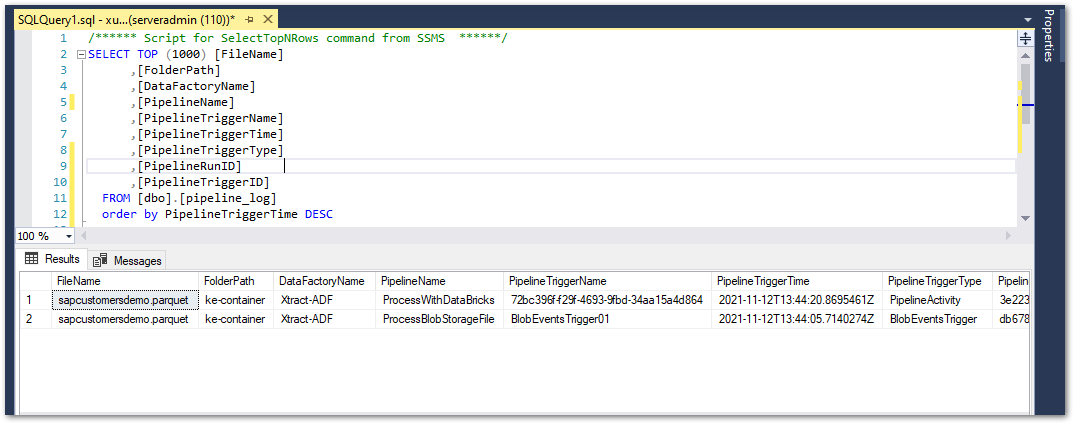
- Check the log table in Azure SQL. The log table shows an entry each for the master and child pipeline.
- Check Trigger and Pipeline Runs in ADF.