This chapter shows best practices about the integration and usage of Xtract Universal with Pentaho Data Integration (ETL) aka Kettle by calling the Xtract Universal HTTP endpoint (aka http-csv destination).
The picture below shows the architecture.
In Pentaho, we execute the extraction using an HTTP call.
Xtract Universal extracts the data from SAP and delivers it via HTTP in CSV format.
In Pentaho, we can then process the delivered data and then load then e.g. to a database.

This scenario would run on any operating system, unlike the command line scenario, which only runs on a Windows operating system. In Xtract Universal, we have defined an extraction with HTTP-CSV Destination.
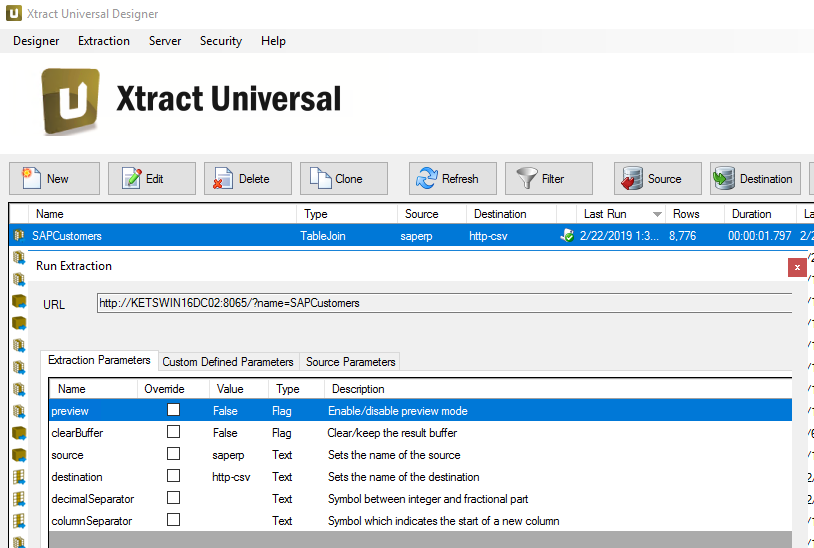
Extraction in Xtract Universal #
Here we see the definition of extraction in Xtract Universal with HTTP-CSV Destination:
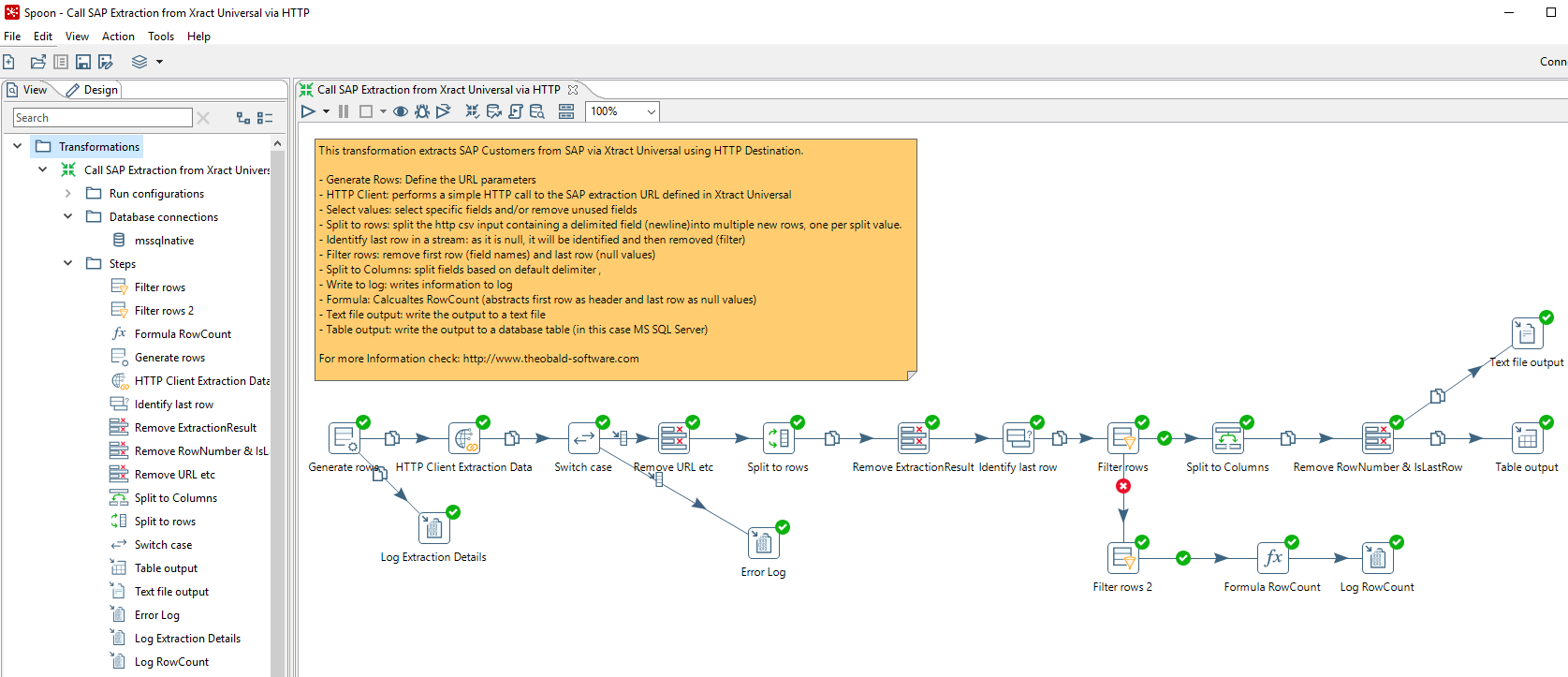
Transformation in PDI #
The overview of the transformation in Kettle shows the steps used:
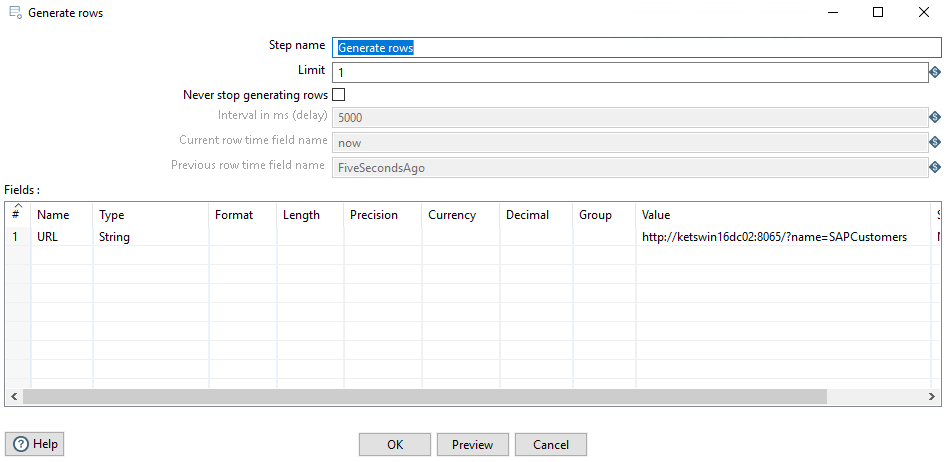
Initial Parameters #
Let’s look at the settings of the important steps. In the first step we define the URL of the extraction in Xtract Universal: http://KETSWIN16DC02:8065/?name=SAPCustomer
HTTP Call #
In the second step, we execute the HTTP call. The URL parameter is passed.
The return is written to the ExtractionResult field. The HTTP status code is also written to a specific field.
The HTTP status code can be used for error handling.
![]()
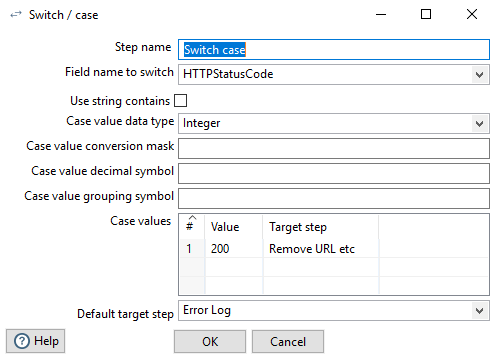
Switch Case #
If the status code is 200, the execution was successful. In case of an error we write to the log.
Split to rows #
We split the result into lines using the line break character.
Note that the first line contains the column names. The last line contains only NULL values.
We will remove these 2 rows later.
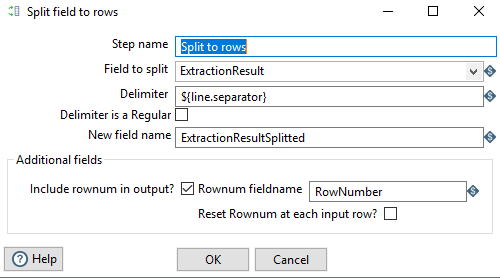 Xtract Universal offers also options to deliver the data without the column names and without a row seperator after the last row, but we are just using the default settings for the http-csv destination.
Xtract Universal offers also options to deliver the data without the column names and without a row seperator after the last row, but we are just using the default settings for the http-csv destination.
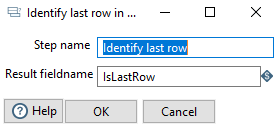
Identity last row #
In this step we identify the last row. The step is helpful when we calculate the number of rows and remove the last row.
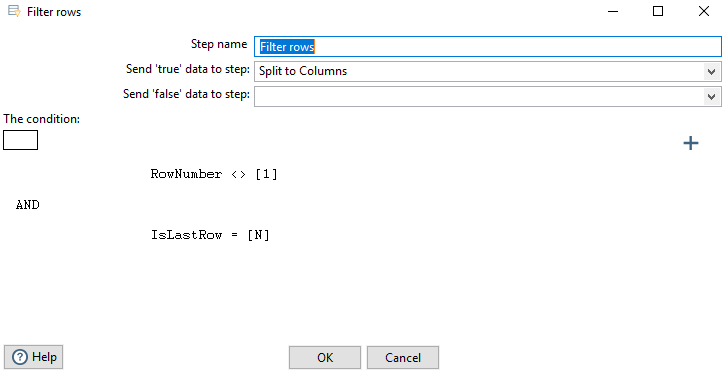
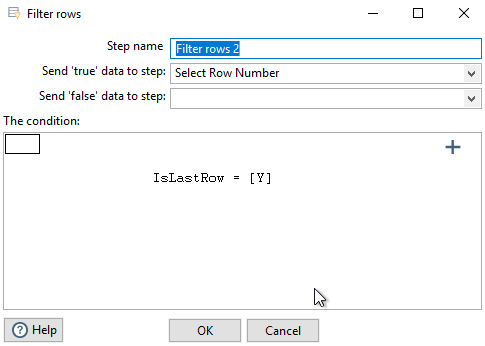
Filter rows #
In this step we remove the first and last rows.
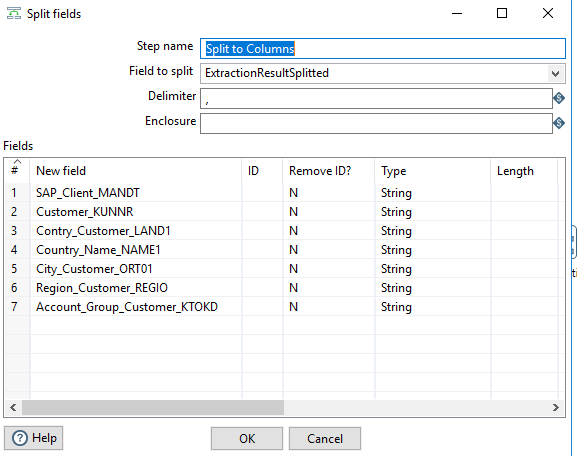
Split to columns #
Data rows are split into columns. In this step we have to define the column names and the data type.
Database Connection #
This is how the connection to the SQL Server looks, which we use to write the data to a table:
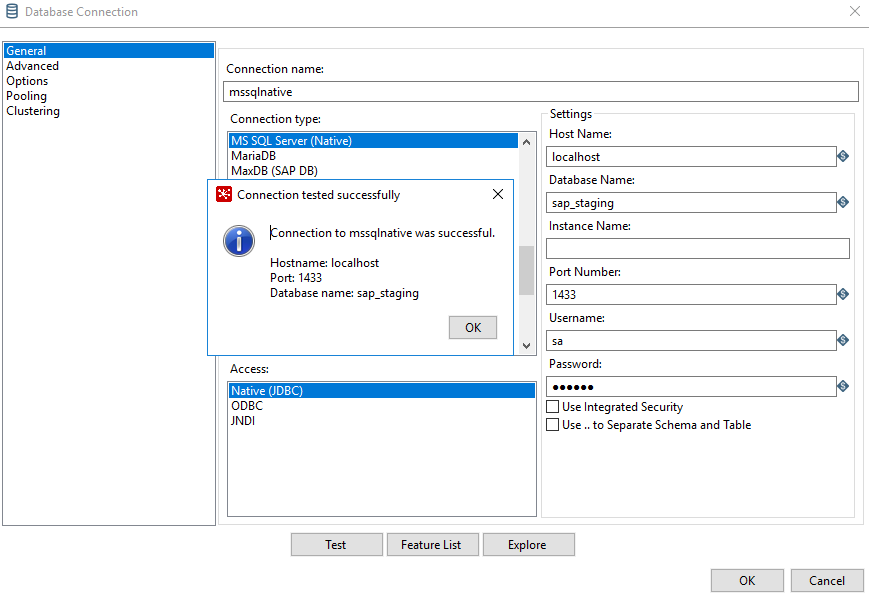
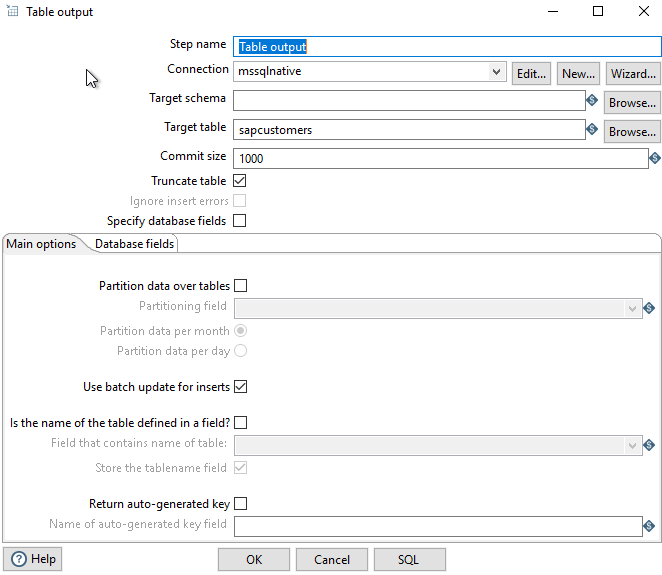
Table output #
We use the following settings for the table output:
File output #
In addition, we write the data to a file. The following settings are used:
![]()
Calculate Number of Rows #
In this branch we want to calculate the number of records.
In this step we remove the first row that contains the original column names. Only the last row remains.
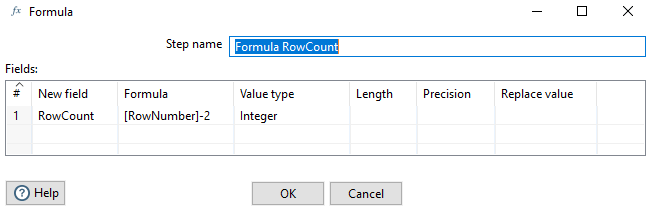
Formula #
Now we can calculate the number of rows.
In this step we write to the log
![]()
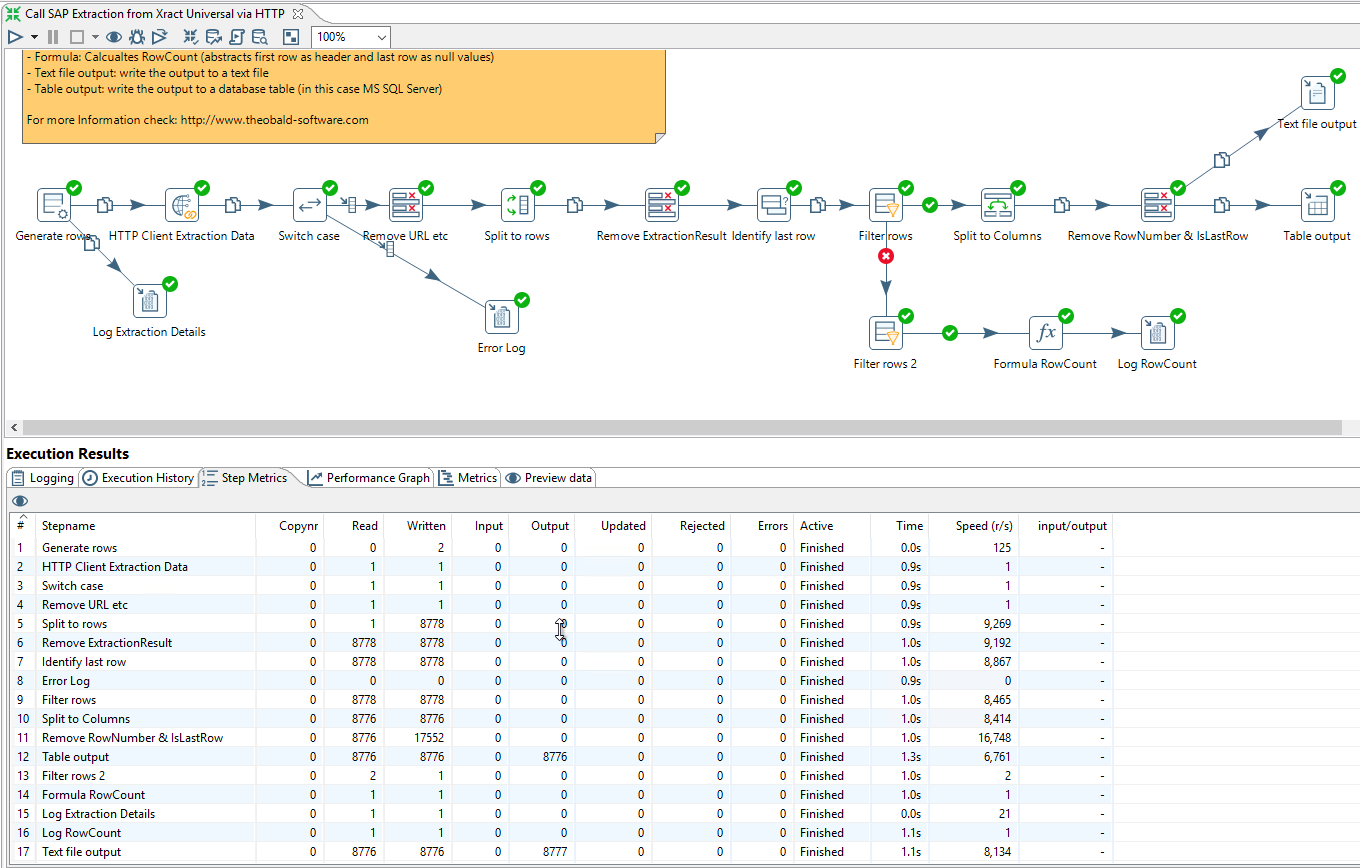
Execute the Transformation in PDI #
After successful execution we can find the metrics.
Preview in PDI #
The preview of the individual steps is also possible.
Preview of the HTTP Call:

Preview of the step split into rows
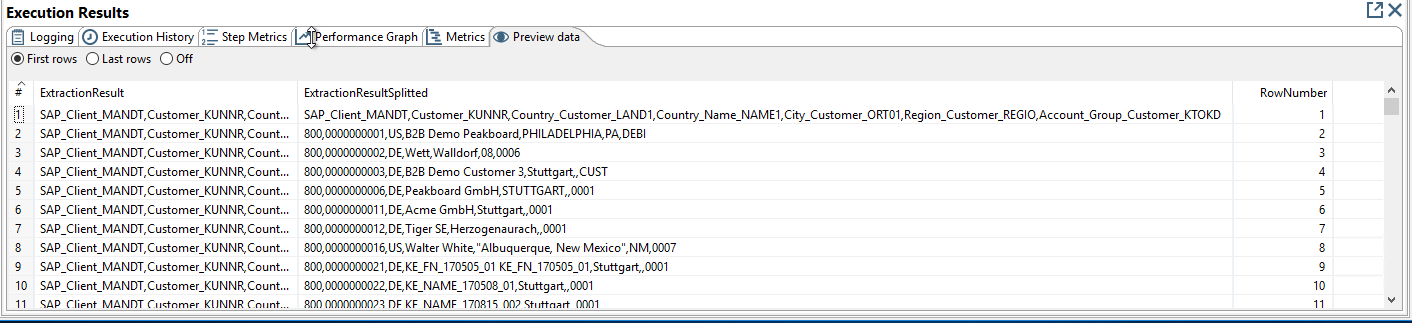
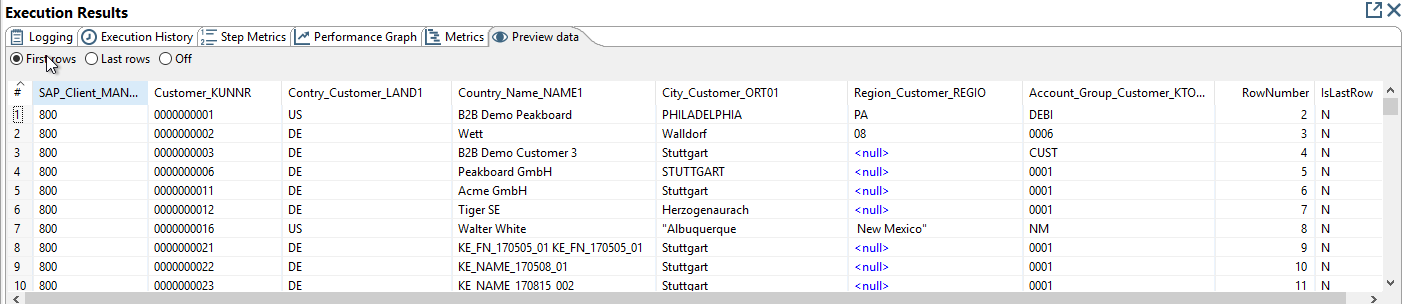
Preview of the step split into columns
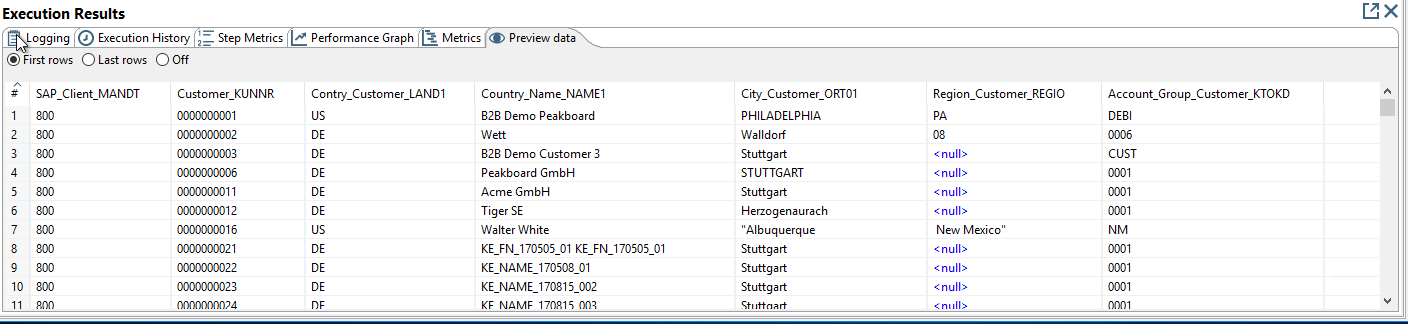
Preview of the data output:
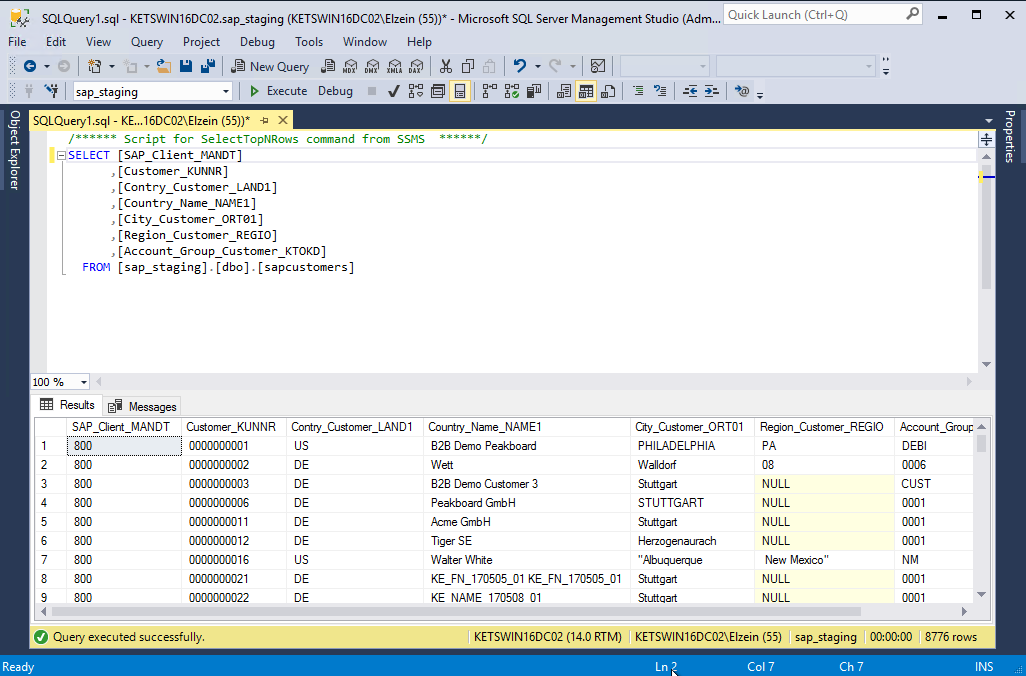
Data im SQL Server #
Here we see the data that we have loaded into the SQL Server:
 {:class=”img-responsive”
{:class=”img-responsive”
In this chapter we have seen how we called and used SAP extractions in Pentaho via HTTP. The SAP extractions are provided by Xtract Universal.
A possible improvement of this scenario would be to extract also the metadata (column name and data type) from Xtract Universal and use it dynamically in the transformation.
Download the transformation template for PDI #
You can download the transformation template for Pentaho Data Integration (PDI) aka Kettle here: Call SAP Extraction from Xract Universal via HTTP.ktr